About us
With the rapid development of AI and the increasing importance of AI Safety, the Singapore AISI will work on addressing the gaps in global AI safety science, leveraging Singapore's work in AI evaluation and testing. It will pull together Singapore's research ecosystem, collaborate internationally with other AISIs to advance the sciences of AI safety and provide science-based input to our work in AI governance. The initial areas of interest are:
- Testing & Evaluation
- Safe Model Design, Development and Deployment
- Content Assurance
- Governance & Policy
At the Digital Trust Centre, home to the AI Safety Institute (AISI), we use trust tech as a key enabler for building digital trust. We aim to leverage technology to foster a secure, ethical ecosystem that supports AI development while safeguarding stakeholder interests. Below are the AI Safety goals of the AISI:

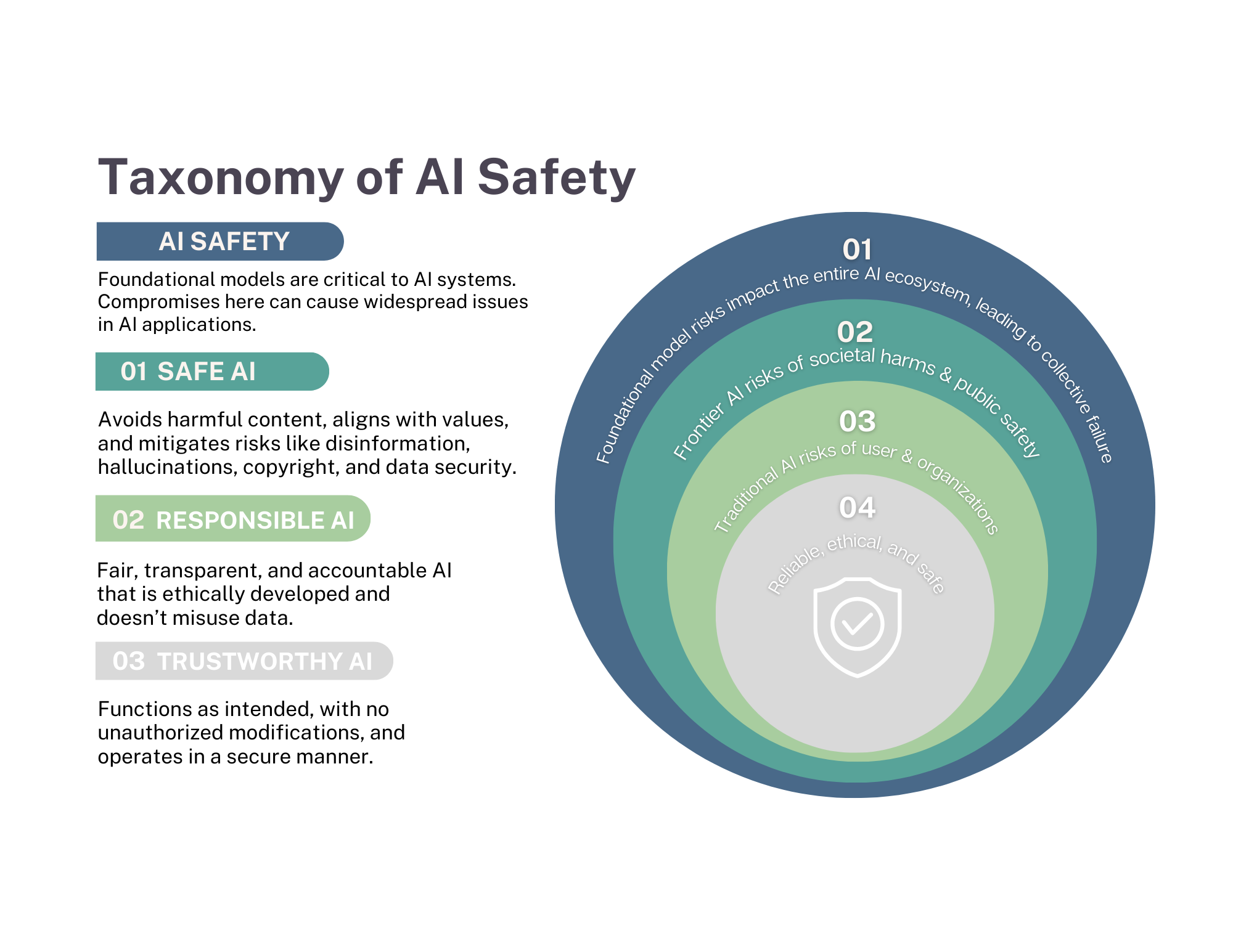
AI Safety
AI safety focuses on identifying and addressing risks in AI models to ensure they function as intended and meet specifications. Our AI Safety Framework highlights trustworthiness, responsibility, and collaboration to mitigate risks across all stages of AI development.
- Trustworthiness: AI must be reliable, perform as expected, and maintain trust in its operation.
- Responsibility: AI-generated errors, such as harmful or inaccurate content, pose significant risks. Governance and accountability are crucial, especially with generative AI, which can produce unintended or misleading content.
- Generative AI Challenges: Foundational models from large companies can lead to failures affecting society, national security, and public safety. Advanced generative AI increases these risks.
- Traditional AI Risks: AI systems can malfunction, undermining trust in their use.
By focusing on the reliable, ethical, and safe development of AI, this framework aims to safeguard public trust and prevent systemic failures within the AI ecosystem.
AI Research
| |
| Prevention of Harmful Content Generation from Large Models | Design comprehensive techniques to prevent the generation of harmful content from different models (e.g., language, image, speech), including effective filtering, red teaming, machine unlearning, and more. |
| Equipping LLM With Vertical Domain Knowledge | Fine-tune LLMs in an instruction-following manner. Research and develop methods capable of generating instructional data from numerous knowledge sources, thereby equipping LLMs with vertical domain knowledge. |
| LLMs as prompt attackers against LLMs (LLMs vs LLMs) | Compared to previous NLP adversarial learning methods (character-level, word-level, and sentence-level), LLMs demonstrate the potential to create adversarial examples that can deceive themselves. To enhance the robustness of LLMs, employ LLMs to attack LLM systems. |
| Distinguishing Human and AI Generated Content | Develop solutions to distinguish between human and machine-generated content for various purposes, such as copyright and plagiarism detection. Propose techniques like watermarking AI-generated content and using LLM-driven detection methods. |
| Source Attribution of Harmful Content Generation | Given malicious media published online, it is essential to identify and hold the creator accountable. Explore robust watermarking techniques for different modalities of AI-generated content. |
| Safety Testing of Generative AI | Develop a testing framework and automated red teaming to comprehensively assess and quantify the vulnerabilities of large models, supporting various modalities, tasks, and security properties. |
| |||
Project Title | Organisation | Framework | Relevant work to AISI |
| Verifiable computation in the face of malicious adversaries | NTU | Trustworthy AI | Enhance LLM |
| Combatting Prejudice in AI: A Responsible AI Framework for Continual Fairness Testing, Repair, and Transfer | A*STAR | Trustworthy AI | Red-Teaming |
Trust Verification of the Knowns and Unknowns in Reinforcement Learning | A*STAR | Trustworthy AI | Address Disinformation and Hallucination |
Towards More Trustworthy Generative AI through Robustness Enhancement and Hallucination Reduction | NTU | Safe AI | Prevent Harmful Generation |
Evaluating, Detecting, and Mitigating the Risks of Diffusion Models for Fair, Robust, and Toxic Content-Free Generative AI | NTU | AI Safety | Red-teaming |
Scalable Evaluation for Trustworthy Explainable AI | NUS | Explainable AI | Enhance LLM |
Related International Efforts

News and Events

Partner Institutions and Agencies
