












/enri-thumbnails/careeropportunities1f0caf1c-a12d-479c-be7c-3c04e085c617.tmb-mega-menu.jpg?Culture=en&sfvrsn=d7261e3b_1)

/cradle-thumbnails/research-capabilities1516d0ba63aa44f0b4ee77a8c05263b2.tmb-mega-menu.jpg?Culture=en&sfvrsn=1bc94f8_1)

ROSE Lab team ranked 5th and 6th globally
Published on: 04-Oct-2016
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is one of the most important competitions in computer vision community since it is a benchmark of several basic problems in this field, e.g., object category classification and detection on hundreds of categories and millions of images. The challenge has been run annually since 2010, with each year's Challenge attracting participation from leading institutions and corporations globally. Past winners include leading technology companies (e.g., Google, Microsoft Research Asia, NEC, etc.) and top universities (e.g., Oxford University, University of Toronto, New York University, etc.).
The 2016 challenge was organized by Stanford University, MIT, Carnegie Mellon University, and UNC Chapel Hill. A total of 85 teams from different universities and companies from all over the world took part in four different tasks of the competition including object detection, object localization, object detection from video, scene classification, and scene parsing. The challenge has been becoming increasingly competitive as the performance bar has been raised significantly compared to last year's outcome: Object detection's mean average precision (mAP) is up to 66.3% from 62.1% last year. Localization error is down to 7.7% compared to 9.0% last year. Classification error is down to 3.0% from 3.6% last year. Object detection from video (VID) mAP is up to 80.8% from 67.8% last year, and is 55.9% with the new metric with tracking information.
The ROSE Lab team focused on the scene classification task and the scene parsing task. The scene classification task aims to classify 368k images into 365 scene categories, with 8 million training images and 36k validation images. The scene parsing task refers to associating one of 150 semantic classes to each pixel over a total number of 2k testing scene images, with 20k training images that are exhaustively annotated with objects and object parts and validated on another 2k such images.
Humans are extremely proficient at perceiving natural scenes and understanding their contents. However, we know surprisingly little about how or even where in the brain we process such scenes. Work on this project requires us to perform an analysis of statistical properties of natural scenes. This type of analysis allows for a deeper understanding of how to process the kinds of images we encounter in everyday life, and for designing the next generation algorithms to approach human-level vision. Potential applications of scene classification and parsing include content-based indexing and organization of images, content-sensitive image enhancement, image understanding, augmented reality/autonomous driving, etc.
Both tasks are very difficult due the large scale of training data (more than 10 million of images in total), noisy class labels, large intra-class variances, and ambiguities among different classes. To address these problems, we build a distributed system performing training simultaneously on multiple GPUs boarded on multiple servers. Also, we adopt the most advanced convolutional neural network, named wide residual network, with our customized implementation. We proposed a novel ensemble protocol that takes multiple activations as extra sources of clues following the training phase. These clues have proved effective in compensating for the flaws of each model and provide better generality power to the data.

Figure 1. Sample images from different categories for scene classification
At the end of the challenge, the ROSE team was ranked 5th world-wide in the scene classification task. The top results on scene classification task are very close, but the ROSE team is the top-ranked university team once again. The ROSE team was also ranked 6th world-wide in the scene parsing task. Overall, our achievement demonstrates that we are a top-tier university research team within the computer vision community. We believe we could get better results in the next year with improved learning strategies, more hardware support and closer collaboration with our partners.

Figure 2. Sample images for scene parsing.
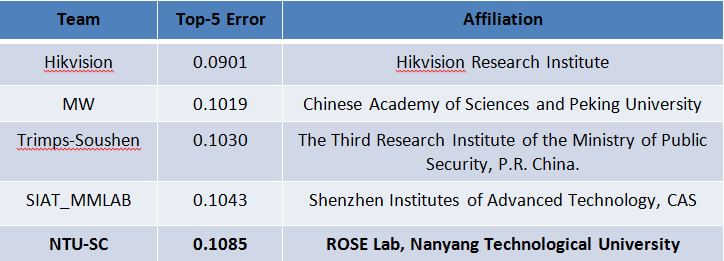
Table 1. Competition results of the scene classification task.
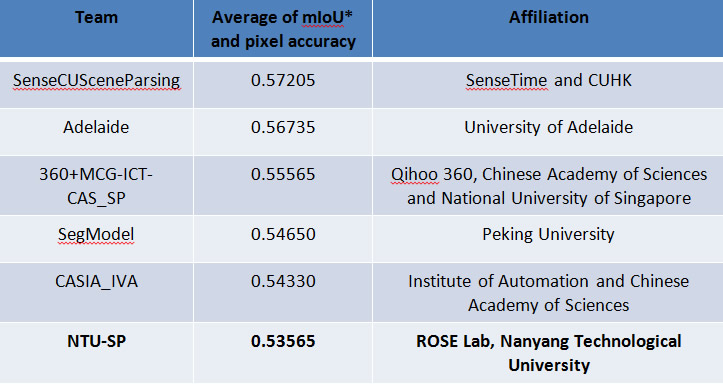
Table 2. Competition results of the scene parsing task.
(*mIoU stands for "mean of intersection over union", a rigorous performance evaluation metric specifically for this task.)