Students' AI-Augmented Thinking
This project aims to understand students’ thinking processes when programming with the supported of generative AI or not; and examine
What factors will impact AI-augmented thinking?
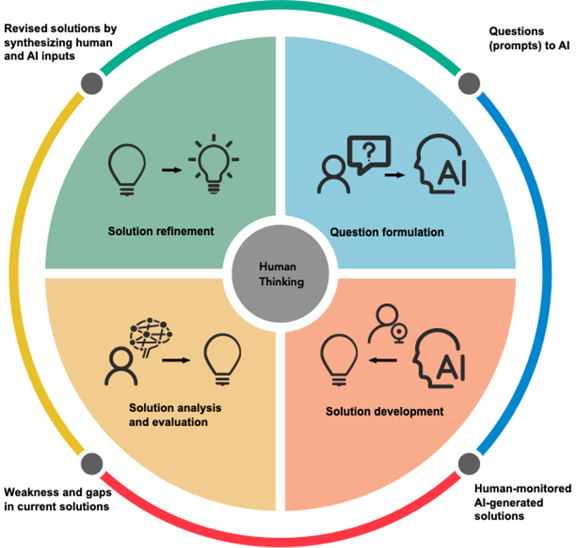
AI-augmented thinking framework constructed based on 20-hour screen recording and discourse with ChatGPT
 |
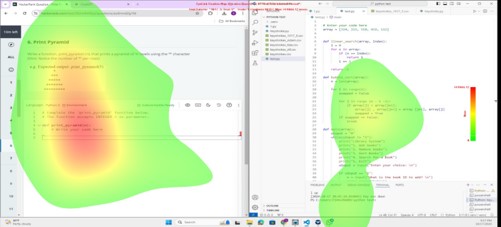
We use eye tracker to examine what do participants pay more attention to (e.g., code, outcomes, output by generative AI) during the programming process.
 Eye gaze heatmap of a participant programming with AI |
|